Technical SEO: The Complete Guide 2026
Most websites publish great content and still get zero traffic. The reason is almost always technical — Google cannot crawl, understand, or trust the site properly.
Fix the technical foundation first, and everything else you do in SEO starts to actually work.
What is Technical SEO?
Technical SEO is the process of making your website easy for search engines to find, read, and understand.
It is not about writing better content. It is not about getting backlinks. It is about the structure and health of your website itself.
Think of it this way. You can write the best book in the world. But if the library cannot find it, no one reads it.
Purpose: Technical SEO makes sure Google can reach your pages, understand what they are about, and decide they are worth showing to users.
How It Differs From On-Page and Off-Page SEO
These three work together, but they are not the same thing.
On-page SEO focuses on what is written on your page — keywords, headings, meta descriptions, internal links. Off-page SEO focuses on what happens outside your site — backlinks, brand mentions, social signals.
Technical SEO focuses on how your website is built. It runs underneath everything else. Around 94% of all webpages receive no traffic from Google — and bad technical SEO is one of the biggest reasons why.
If Google cannot crawl your page, the quality of your content does not matter. Zero traffic is zero traffic, no matter how good the writing is.
How Search Engines Actually Work
Before you fix technical issues, you need to understand what search engines do. There are three stages: crawling, indexing, and rendering.
Crawling: How Google Discovers Pages
Crawling is the process of Google sending bots (called Googlebots) to visit your website and collect information about your pages.
These bots move from page to page using links. They also follow your XML sitemap to find pages directly. Two things help them the most — internal links and your sitemap. Two things block them — a badly written robots.txt file and too many pages with no links pointing to them.
Here is the simplest example: you publish a new blog post but do not link to it from anywhere on your site. Google may never find it. Not in a week. Not in a month. Ever.
Indexing: How Google Decides What to Store
After crawling a page, Google decides whether to add it to its index. The index is the database Google pulls from when someone searches.
Pages that do not get indexed do not appear in search results.
Pages fail to get indexed for a few reasons. They may have a “noindex” tag telling Google to skip them. They may be too thin — not enough content to be useful. They may be duplicate versions of another page. Or they may simply be blocked in the robots.txt file.
Rendering: How Google Reads Your Content
Rendering is the process of Google loading your page the way a browser would, including JavaScript and CSS.
This is critical for modern websites. Many sites load content through JavaScript. If Google cannot render that JavaScript, the content is invisible to it — even though a human visitor sees it perfectly.
The Core Components of Technical SEO
1. Website Crawlability
Crawlability means Google can actually access your pages without obstacles.
Three things control crawlability more than anything else.
Your robots.txt file tells search engines which parts of your site they can and cannot visit. A single mistake in this file — like accidentally blocking your entire site — can wipe your rankings overnight.
Crawl depth refers to how many clicks it takes to reach a page from your homepage. If a page is six or seven clicks deep, Google assigns it lower priority. Important pages should be reachable in three clicks or fewer.
Broken links are another crawler trap. When Googlebot follows a link that leads to a dead page (a 404 error), it wastes crawl resources and stops moving through that path of your site.
2. Indexability
You can have a crawlable site and still have indexing problems.
The canonical tag is one of the most important tools here. It tells Google:
“This is the main version of this page. Ignore the others.”
Without it, Google may find several versions of the same page — with and without “www,” with and without trailing slashes — and treat them as duplicate content.
The difference between “noindex” and “disallow” confuses a lot of people.
Disallow (in robots.txt) tells Google not to crawl a page.
Noindex (in the page’s HTML) tells Google to crawl it but not include it in search results. They do very different things.
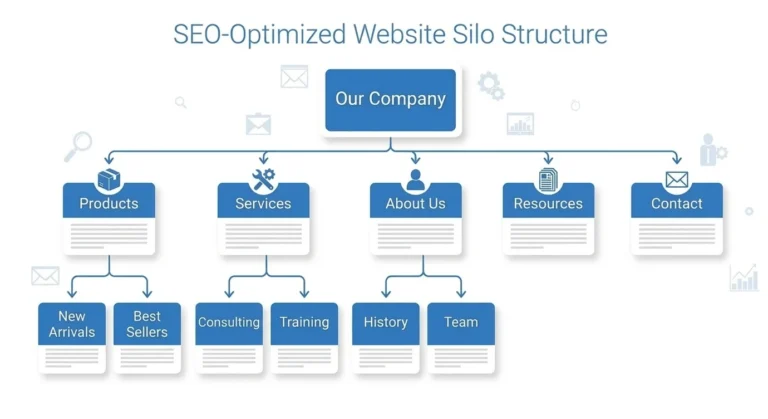
3. Site Architecture
Site architecture is how your pages are organized and connected.
A flat structure means most pages are reachable in just a few clicks from the homepage. A deep structure buries important pages behind many layers of navigation.
An important product page buried six clicks deep gets treated like a low-priority page — because from Google’s point of view, the number of internal links pointing to a page signals how important that page is.
Internal linking strategy should follow this logic: the more important the page, the more internal links should point to it. Your most valuable pages should be linked from your homepage, your navigation, and from related content throughout your site.
4. Page Speed and Core Web Vitals
When pages load in 1 second, average goal conversion rate is close to 40%, falling to around 34% at 2 seconds and declining further as load time increases.
Speed is not just a user experience issue. It directly affects your rankings.
Google uses three metrics to measure page experience.
LCP (Largest Contentful Paint) measures how quickly the main content loads — it should be under 2.5 seconds.
INP (Interaction to Next Paint) measures how fast your page responds when someone clicks or types — it should be under 200 milliseconds.
CLS (Cumulative Layout Shift) measures visual stability — how much your page jumps around as it loads — and it should be below 0.1.
Only 33% of websites meet the standards set by Google’s Core Web Vitals. That means two out of three websites are already behind on this.
5. Mobile-Friendliness
Mobile generates 58% of all Google searches. Google uses mobile-first indexing, which means it crawls and indexes the mobile version of your site first.
If your desktop site has great content but your mobile version strips it out or hides it, Google is indexing the weaker version. This matters more than most people realize.
Responsive design — where your site automatically adjusts to any screen size — is the standard fix. But responsive design alone is not enough. You also need to make sure text is readable without zooming, buttons are easy to tap, and content loads fast on a mobile connection.
6. Structured Data (Schema Markup)
Structured data is code you add to your page to help Google understand exactly what the content is about.
Without schema, Google has to guess. Is this page a recipe? A product? A review? An event? With schema, you tell Google directly.
72% of first-page results use schema markup, making their listings eligible for rich results like review stars, FAQs, prices, or event details. Still, 23% of websites have no structured data at all.
Schema does not directly boost your rankings. But it makes your listing in search results look richer — with stars, prices, FAQs shown right in Google — and that increases click-through rates significantly.
Common Technical SEO Issues (And How to Fix Them)
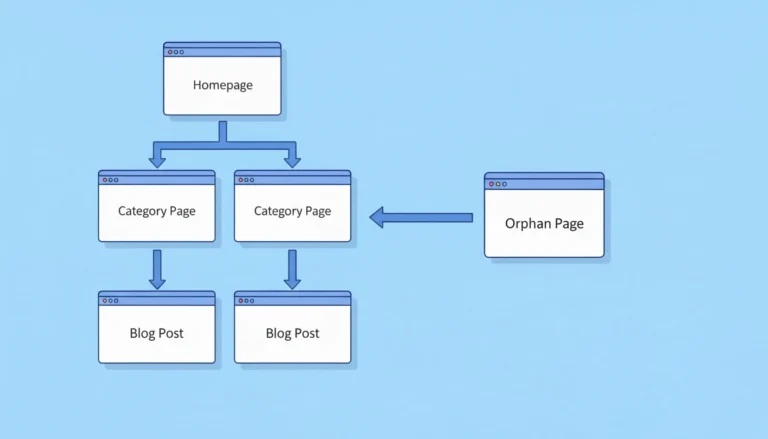
1. Orphan Pages
An orphan page is a page on your site that no other page links to.
Google discovers pages through links. If no page links to a certain page, Google’s bot may never find it. Even if it is indexed, it receives no internal authority and ranks poorly.
How to find them: crawl your site with a tool like Screaming Frog, then compare the list of crawled pages against your sitemap. Pages in the sitemap but not discovered through internal links are likely orphans.
Fix: add internal links to those pages from relevant content already on your site.
| Issue | Problem | Fix |
|---|---|---|
| Orphan page | Not discoverable via internal links | Add internal links from relevant pages |
| Duplicate content | Google splits authority between versions | Add canonical tags |
| Crawl budget waste | Google ignores important pages | Block low-value pages in robots.txt |
| Broken links | Crawl paths stop dead | Redirect 404s or update links |
| Slow pages | Poor Core Web Vitals score | Compress images, reduce JavaScript |
2. Duplicate Content
Duplicate content happens when the same content appears at multiple URLs.
This happens more often than people expect.
- HTTP and HTTPS versions of a page.
- URLs with and without trailing slashes.
- Pages with URL parameters like
?ref=emailor?sort=price. - Printer-friendly versions of pages.
All of these can create duplicates.
Google does not penalize duplicate content the way some people claim. But it does split ranking signals between the duplicate versions, weakening both.
Use canonical tags to point Google to the correct version.
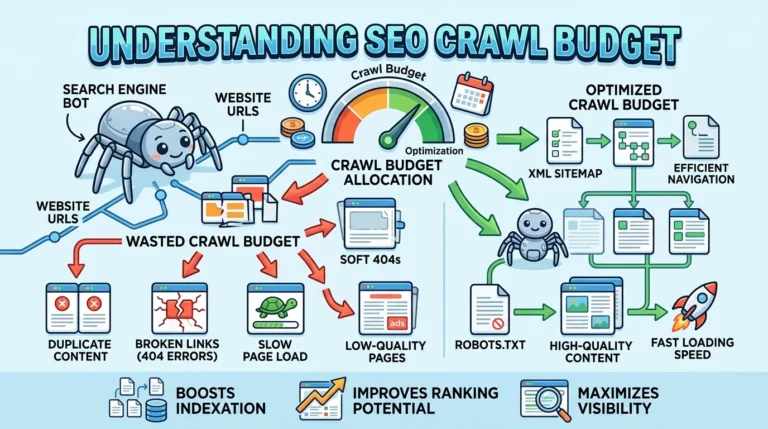
3. Crawl Budget Waste
Crawl budget is the number of pages Googlebot is willing to crawl on your site in a given period.
For small sites with a few hundred pages, this rarely matters.
For large sites with tens of thousands of pages, it is critical.
If Google spends its crawl budget on low-value pages — old session URLs, infinite filter combinations, staging content — it may miss your important pages entirely.
Fix: use robots.txt to block low-value URLs, and make sure your sitemap only includes pages you actually want indexed.
4. Broken Links and Redirect Chains
A broken link leads to a 404 page. A redirect chain happens when a URL redirects to another URL, which redirects to another URL, and so on.
Both waste crawl budget. Redirect chains also dilute the link authority that should flow to your destination page. Every hop in a redirect chain loses some of that value.
Fix broken links by redirecting them directly to the live destination page. If you have redirect chains, collapse them — go directly from the original URL to the final destination in one step.
How to Do a Technical SEO Audit (Step by Step)
Step 1: Crawl Your Website
Use a tool like Screaming Frog, Sitebulb, or Ahrefs Site Audit.
Crawl the entire site and export the results.
You are looking for: 404 error pages, redirect chains, missing meta titles or descriptions, duplicate page titles, and pages blocked from crawling.
If you found, then you need to fix.
Step 2: Check Index Coverage in Google Search Console
Open Google Search Console. Go to Index Coverage. Here you will see exactly which pages Google has indexed and which it has not — and the reason why. Look for pages flagged as “Crawled but not indexed,” “Excluded by noindex,” or “Duplicate without user-selected canonical.”
Step 3: Fix Crawl Errors
Take the list of 404 pages and either redirect them to the most relevant live page or restore them if they should exist. Fix any pages accidentally blocked in robots.txt. Collapse redirect chains to single-hop redirects.
Step 4: Improve Internal Linking
Find your highest-traffic pages using Google Search Console or Ahrefs. Then find orphan pages or low-authority pages that should rank but do not. Add internal links from your high-traffic pages to those weaker pages. This passes authority where it is most needed.
Step 5: Optimize Page Speed
Run every key page through Google PageSpeed Insights. Focus on the three biggest wins first: compress your images (use WebP format), reduce unused JavaScript, and enable browser caching. A page that loads in 1 second converts at nearly double the rate of a page that loads in 4 seconds — this is not a minor issue.
The workflow is simple: Crawl → find errors → fix 404s with redirects → update internal links → measure speed → compress and simplify.
Tools for Technical SEO
Google Search Console — free, made by Google, shows exactly how Google sees your site. Check it weekly. It tells you which pages are indexed, which have errors, and which have Core Web Vitals problems.
Screaming Frog — crawls your website the way Googlebot does. Finds broken links, duplicate content, missing tags, redirect chains, and orphan pages. The free version handles up to 500 URLs.
Google PageSpeed Insights — tests your page speed and Core Web Vitals. Free. Shows both mobile and desktop scores and tells you exactly what to fix.
Ahrefs Site Audit — a cloud-based crawler that runs regular audits and tracks technical health over time. Good for large sites that need ongoing monitoring.
Semrush Site Audit — similar to Ahrefs, with strong reporting on crawlability and technical issues. Useful for client reporting.
Log File Analyzers (like Screaming Frog Log Analyzer or Splunk) — show you exactly which pages Googlebot is visiting, how often, and which it is skipping. Critical for large sites where crawl budget matters.
Technical SEO Checklist
Use this before and after every site audit.
Crawling
- Can Google crawl all important pages?
- Is robots.txt blocking anything it should not?
- Are there broken links (404s) that need redirecting?
- Are there redirect chains longer than one hop?
Indexing
- Are all important pages appearing in Google Search Console’s index?
- Are canonical tags set correctly on duplicate URLs?
- Are any pages accidentally tagged with noindex?
- Are thin or low-value pages blocked from being indexed?
Site Architecture
- Can you reach every important page in three clicks or fewer from the homepage?
- Are orphan pages connected to the rest of the site via internal links?
- Do your most important pages have the most internal links pointing to them?
Speed and Experience
- Does your site pass Core Web Vitals for LCP, CLS, and INP?
- Are images compressed and in a modern format like WebP?
- Is unnecessary JavaScript removed or deferred?
Mobile
- Does your site render correctly on mobile?
- Is the mobile version of your content identical to the desktop version?
Structured Data
- Do key pages (products, articles, FAQs) have schema markup?
- Is the schema valid? (Test with Google’s Rich Results Test tool)
Frequently Asked Questions
What is technical SEO in simple terms?
Technical SEO is the process of making your website easy for search engines like Google to find, access, and understand. It covers how your site is built — its speed, structure, crawlability, and code — rather than the content you write.
Why is technical SEO important?
Without technical SEO, even excellent content may never appear in search results. If Google cannot crawl your pages, it cannot index them. If it cannot index them, they cannot rank. 94% of all webpages get zero traffic from Google — poor technical foundations are a major reason why.
How long does technical SEO take to show results?
It depends on the size of the site and how severe the issues are. Simple fixes like removing noindex tags or adding canonical tags can show results in days. Bigger changes like improving site speed or restructuring site architecture typically take 3 to 6 months to fully reflect in rankings.
What are the most common technical SEO issues?
The most common issues are: slow page speed, pages not indexed due to noindex or thin content, duplicate content without canonical tags, broken links causing 404 errors, and orphan pages that receive no internal links.
How do I do a technical SEO audit?
Crawl your site with Screaming Frog or a similar tool. Check Google Search Console for index coverage errors. Fix 404 pages with redirects. Add canonical tags to duplicate URLs. Improve internal linking to important pages. Run PageSpeed Insights on your key pages. Then track the changes in Search Console over the next 60 to 90 days.
What is crawl budget and when does it matter?
Crawl budget is the number of pages Google will crawl on your site within a set timeframe. For most small sites, it does not matter. For sites with more than 10,000 pages, it becomes critical. Wasting crawl budget on low-value pages means Google may miss your most important pages entirely.
Does technical SEO affect rankings directly?
Yes. Page speed, mobile-friendliness, Core Web Vitals, and structured data are all confirmed Google ranking factors. Crawlability and indexability determine whether a page can rank at all. Technical SEO is not a bonus — it is the minimum requirement for anything else to work.
Most SEOs jump straight into content and backlinks. But if your site has crawlability issues, duplicate content problems, or pages loading in five seconds on mobile, you are building on sand.
Get the technical foundation right, and every piece of content you publish, every backlink you earn, and every optimization you make starts compounding. That is when SEO stops feeling like guesswork and starts working like a system.

Senior SEO Analyst with 5+ years experience. I specialize in Local SEO, Technical SEO, and AI search visibility through AEO and GEO strategies. Everything I write is tested against real search performance, not borrowed from someone else’s playbook.